The Enterprise Content Audit That Actually Scales: How to Fix What's Killing Your Rankings Across 10,000+ Pages
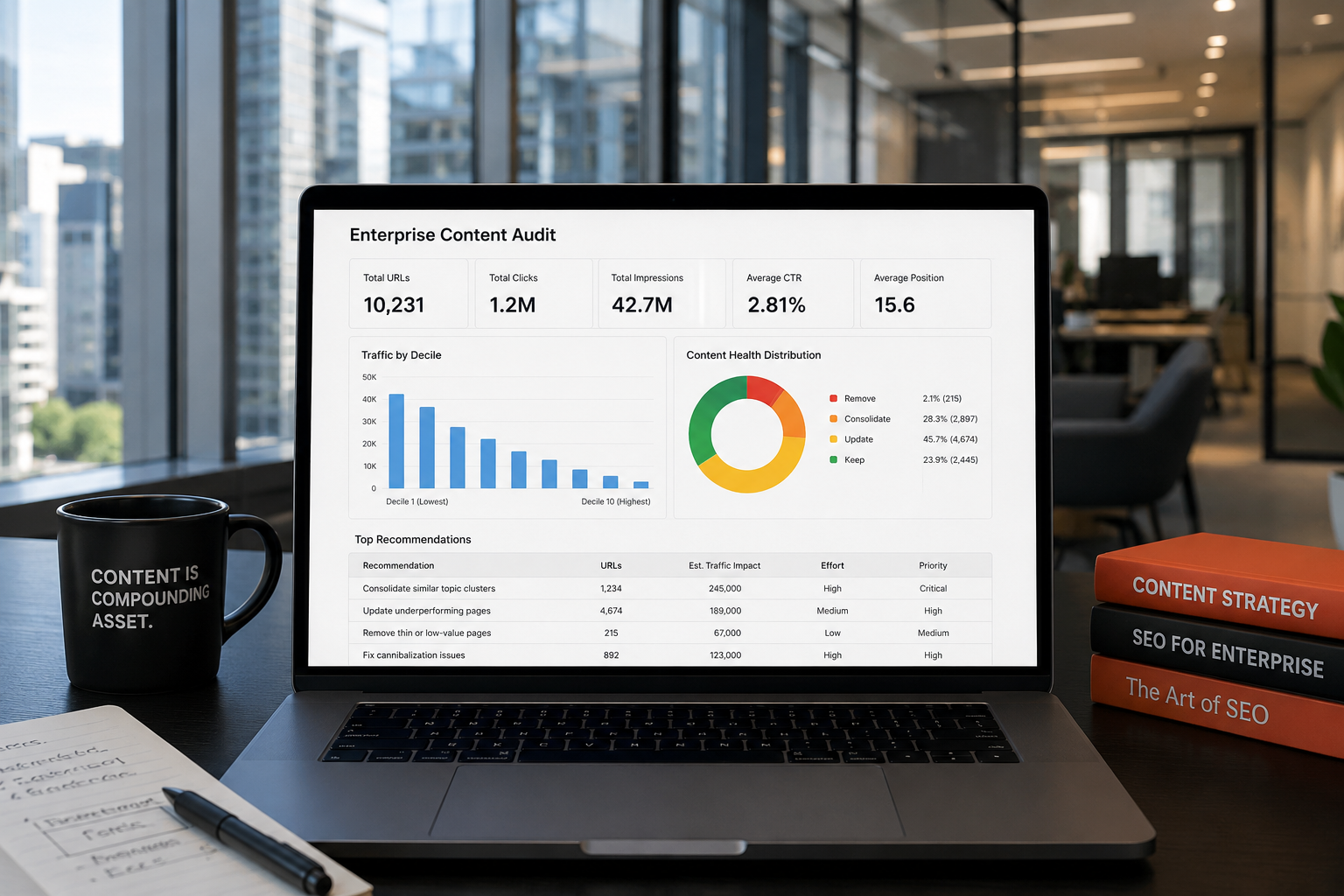
Large websites accumulate content debt the same way large companies accumulate technical debt: gradually, invisibly, and expensively. When a significant portion of your page inventory is actively suppressing your domain's authority — through topical cannibalization, zombie pages, and thin content that dilutes trust signals — your highest-value pages rank lower than they should, your AI citation share is weaker than it could be, and your organic pipeline contribution is a fraction of what the asset is capable of producing. A properly scoped content audit identifies and fixes that debt, and the ROI is typically faster and larger than an equivalent investment in new content production.
That's the brief. The rest of this post is for the team that runs it.
The Problem With How Enterprise Content Audits Usually Get Done
Most enterprise content audits start with a spreadsheet and end with a spreadsheet. Someone exports all URLs from a crawl tool, adds GSC data, sorts by traffic, flags the low performers, and produces a recommendation list that's either too long to action or too vague to implement.
The result is a document that accurately describes the problem and does almost nothing to solve it. The pages stay live. The cannibalization continues. The authority dilution compounds. And six months later, someone runs the same audit and produces the same spreadsheet.
The reason this keeps happening isn't bad intentions or lazy execution. It's that most content audit frameworks weren't designed for the scale, the organizational complexity, or the decision-making structure of an enterprise website. They were designed for sites with a few hundred pages, where one person can hold the full picture in their head and make decisions in a single afternoon.
At 10,000 pages, that doesn't work. You need a framework that scales — one that's systematic enough to process thousands of URLs without requiring manual judgment on every single one, but specific enough to surface the decisions that actually require human expertise.
This is that framework.
The Three Problems That Are Actually Killing Your Rankings
Before getting into the audit process, it's worth being precise about what you're auditing for. At enterprise scale, there are three distinct content problems that suppress organic performance, and they require three distinct diagnostic approaches.
Problem 1: Topical Cannibalization
Topical cannibalization happens when multiple pages on your site target the same or closely related search intent, splitting the authority signals that should be concentrated on a single authoritative page. Google and AI retrieval systems both face the same problem: when they see five pages on your domain all appearing to answer the same question, they have to decide which one to surface. They often make that decision inconsistently, surface the wrong one, or suppress all of them in favor of a competitor with a single, authoritative treatment of the topic.
At enterprise scale, cannibalization is almost always unintentional. It accumulates over years of content production by different teams, different agencies, and different content calendars — none of which had visibility into what the other had already produced. A company that has been publishing blog content for eight years almost certainly has multiple posts targeting variations of the same core queries. The individual pages look fine in isolation. The portfolio of pages is quietly suppressing each other.
The symptoms of topical cannibalization are specific: rankings that plateau despite strong content quality, position instability where the same query surfaces different pages on different days, and click data concentrated on one page while impressions are spread across several. GSC query data is usually the fastest way to identify it — when the same query is returning multiple pages from your domain in the "pages" view, you have a cannibalization issue.
Problem 2: Zombie Pages
Zombie pages are pages that exist, are indexed, and consume crawl budget and authority signals without producing any measurable value. They're not necessarily bad content — they're often content that was relevant at some point and simply stopped being relevant. Product pages for discontinued offerings. Blog posts covering topics that have been superseded by more recent work. Landing pages for campaigns that ended two years ago. Location pages for offices that no longer exist.
At enterprise scale, zombie pages are endemic. A company that has been operating its website for a decade and publishing regularly has almost certainly accumulated hundreds or thousands of pages that should either be updated, consolidated, or removed. Modern search systems no longer compensate for structural shortcuts. AI-driven systems amplify inconsistency — retrieval becomes selective, and structural debt compounds. Every zombie page that consumes crawl budget is a page that could have been spent on your highest-value content. Every thin, outdated page that stays indexed is a signal that dilutes your domain's overall quality assessment. Search Engine Journal
The diagnosis for zombie pages is simpler than for cannibalization: pages with zero or near-zero impressions over a 12-month window that also have no inbound links, no conversion events, and no strategic reason to exist are candidates for consolidation or removal.
Problem 3: Authority Dilution at Scale
Authority dilution is the aggregate effect of the first two problems, compounded by the sheer volume of low-quality, low-intent, and off-topic content that accumulates on large sites over time. It's the reason a domain with strong brand recognition, significant backlink profile, and genuinely good content on its core topics still underperforms in rankings — because Google and AI retrieval systems are evaluating the whole domain, not just the good pages.
The clearest signal of authority dilution is the gap between your domain's overall authority metrics and the actual ranking performance of your best pages. When pages that should dominate their topic — based on content quality, backlink profile, and brand strength — are consistently outranked by smaller competitors with weaker domains, authority dilution is almost always part of the explanation.
Fixing it requires not just identifying the problem pages but understanding which ones are actively harming the domain's quality signals versus which ones are simply neutral. That distinction determines whether a page gets updated, consolidated, noindexed, or removed — and getting it wrong wastes significant resources.
The Framework: Four Phases That Actually Work at Scale
Phase 1: Inventory and Segmentation (Week 1–2)
The first mistake most enterprise audits make is trying to audit everything at once. At 10,000+ pages, that's not an audit — it's a data project that takes three months and produces insights that are already stale by the time anyone acts on them.
The correct approach is segmentation. Before you analyze a single page, segment the full URL inventory into meaningful buckets that can be audited independently with different criteria and different decision frameworks.
The segments that matter at enterprise scale:
Core product and service pages — the pages that directly support commercial intent and are closest to conversion. These get the most intensive analysis and the most conservative treatment. You don't remove or noindex a core product page without substantial evidence and stakeholder alignment.
Informational content — blog posts, guides, whitepapers, FAQs. This is typically the largest segment and the one with the most debt. These pages get analyzed for cannibalization, topical relevance, and traffic trajectory.
Supporting pages — about, team, location, legal, and other pages that serve a function but rarely drive organic traffic. These get a lighter-touch audit focused primarily on indexation decisions and crawl budget efficiency.
Orphaned pages — pages with no internal links pointing to them. At enterprise scale, there are almost always hundreds of these. They're low-hanging fruit: either add internal links if the page has value, or remove if it doesn't.
Segmenting the inventory before analysis means you're making decisions within the right context for each page type, using the right criteria, with the right stakeholders involved. A core product page and a three-year-old blog post about an industry trend that no longer exists are not the same type of decision.
The data you need for Phase 1:
Full URL inventory from a crawl tool — Screaming Frog, Sitebulb, or equivalent. At 10,000+ pages, you'll need a tool that can handle the scale without sampling.
12 months of GSC data at the page level — clicks, impressions, average position, and queries. Export at full resolution, not aggregated.
Google Analytics or equivalent — sessions, engagement rate or bounce rate, conversion events by page.
Backlink data at the page level — which pages have external links pointing to them and from where.
With these four data sources segmented by page type, you have the foundation for every decision that follows.
Phase 2: Triage and Classification (Week 2–4)
Phase 2 is where the actual audit happens — but against the segmented inventory, not the full URL list. The goal is to classify every page into one of four categories using a consistent decision framework that doesn't require manual judgment on every individual URL.
The four classifications:
Keep and optimize — pages with meaningful traffic or strategic value that are underperforming their potential. These need diagnosis: why isn't this page ranking better, and what's the highest-leverage fix?
Consolidate — pages that overlap significantly with other pages in the inventory. The consolidation decision involves picking a canonical target, redirecting the others, and migrating the best content from the consolidated pages into the surviving one.
Update — pages that have traffic or authority value but whose content is stale, thin, or no longer aligned with current search intent or AI retrieval criteria.
Remove or noindex — pages with no traffic, no backlinks, no conversion value, and no strategic reason to exist. These get either removed with a redirect to the most relevant surviving page, or noindexed if they need to exist for operational reasons but shouldn't be consuming crawl budget.
The scoring model that makes Phase 2 scalable:
The reason most enterprise audits bog down in Phase 2 is that every page becomes a discussion. Does this page have potential? Should we update it or consolidate it? Who owns this content? What did the 2022 team intend when they published it?
The way to avoid that is a scoring model that makes most decisions automatically, reserving human judgment for the edge cases. The model should score each page on four dimensions:
Traffic signal — impressions and clicks over the last 12 months. A page with zero impressions and zero clicks in 12 months starts with a strong presumption toward removal or noindex.
Authority signal — inbound links from external domains. A page with no external links has no link equity that needs to be preserved or redirected carefully.
Conversion signal — does this page produce any measurable commercial outcome? Form fills, demo requests, content downloads, time-on-site from high-intent traffic.
Strategic signal — does this page exist for a reason that the traffic data doesn't capture? A page that gets no organic traffic but is regularly shared in sales conversations or linked from partner sites has value that the data doesn't show.
Pages that score low on all four dimensions get classified for removal without discussion. Pages that score high on at least one dimension get a manual review. The model handles 70 to 80% of the inventory automatically. Human judgment is concentrated on the 20 to 30% where it actually matters.
Phase 3: Cannibalization Mapping (Week 3–5, runs parallel to Phase 2)
Cannibalization mapping runs in parallel with the triage process because it requires a different analytical lens. You're not evaluating pages individually — you're evaluating groups of pages that compete with each other.
The process:
Export all queries from GSC that are returning more than one page from your domain in the "pages" view. This is the raw cannibalization signal — every query on this list has at least two pages on your site competing for the same intent.
Group those queries by topic cluster. The individual query "enterprise content audit" and the query "how to audit website content at scale" might both appear on this list, and both might be mapped to pages that are cannibalizing each other. Grouping by topic cluster rather than individual query gives you the full picture of how your content inventory is organized around each topic.
For each topic cluster with cannibalization, identify the canonical page — the one that should own this topic based on content quality, backlink profile, and conversion relevance. In a well-functioning content architecture, every topic has a clear canonical page and all supporting content points to it. In most enterprise websites after years of uncoordinated content production, there is no clear canonical page — there are three or four pages that all partially address the topic, none of which are comprehensive enough to dominate it.
The fix is consolidation plus internal linking. The canonical page gets updated to be the definitive resource on the topic. The competing pages get redirected to the canonical page if they have no unique value, or restructured to cover a clearly differentiated angle if they do. Internal links from across the site get updated to point to the canonical page consistently.
For AI search specifically, this matters beyond traditional SEO. Entity authority is the degree to which search systems recognize your brand as a credible, well-corroborated source on a specific topic. Search systems evaluate entity authority on three dimensions: recognition, relationships, and corroboration. A fragmented set of pages covering the same topic sends weak entity signals. A single, authoritative, well-linked canonical page sends strong ones — and is far more likely to be cited in AI-generated answers than the diluted alternative. Search Engine Journal
Phase 4: Implementation Sequencing and Governance (Week 4–8 and ongoing)
The phase where most enterprise content audits die is implementation. The audit is complete, the recommendations are clear, and then — nothing happens. The dev backlog is full. The content team doesn't have bandwidth. Legal needs to review the removal decisions. The stakeholders who own certain pages won't approve their removal.
Implementation sequencing is the difference between an audit that produces a deliverable and an audit that produces results.
The sequencing principle: implement in order of impact-to-effort ratio, not in order of what you discovered first.
High-impact, low-effort actions go first: noindexing pages with zero traffic and no backlinks requires no content production and minimal dev work. Fixing internal linking to consolidate authority toward canonical pages can often be templated and batched. Updating meta titles and descriptions on near-page-one pages to improve CTR is fast and measurably effective.
High-impact, high-effort actions get scoped as projects: page consolidations that require content migration, canonical redirects that need careful redirect mapping, and full page rewrites for high-value pages with stale content. These go into the roadmap with owners, timelines, and success metrics.
Low-impact actions — pages that are fine but not great, small structural fixes, minor optimization opportunities — go to the backlog and get addressed when capacity allows.
Governance is the ongoing requirement:
The enterprise content audit isn't a one-time project. It's the establishment of a content governance system. AI engines weigh recency when selecting sources — a guide published in 2024 with no updates will lose ground to a 2026 article on the same topic. The infrastructure that makes the initial audit actionable — the segmentation model, the scoring framework, the cannibalization monitoring — needs to run on a continuous basis, not every two years when performance has deteriorated enough to justify another project. Search Engine Land
The governance system should include a quarterly content performance review against the same metrics used in the initial audit, a new content intake process that checks for cannibalization before publishing, and a regular crawl health check that flags new zombie pages before they accumulate. With these systems in place, the content debt stays manageable rather than compounding to the point where another 10,000-page audit is required.
The AI Search Dimension: Why This Matters Beyond Google Rankings
Everything described above applies to traditional Google rankings. For enterprise organizations also investing in AI search visibility — and at this point, that should be every B2B organization with a significant content operation — there's an additional reason to run this audit now.
AI retrieval systems evaluate content at the domain level before they evaluate it at the page level. LLMs do not rank pages in isolation. They extract facts, assess credibility, and generate responses based on inferred relevance. Traditional crawlers index content. LLMs interpret and predict. A domain with structural content debt — cannibalized topics, zombie pages diluting quality signals, fragmented entity authority — sends weaker credibility signals to AI retrieval systems than a structurally clean domain with clear topical authority. Adobe
The content audit is not just an SEO project. It's the prerequisite for effective GEO. You cannot build strong AI citation share on top of a content architecture that confuses search systems about what your domain actually stands for. Fixing the foundation first makes everything that comes after — the content structured for AI synthesis, the entity authority development, the citation measurement — produce better results faster.
The enterprise content audit that actually scales doesn't end with a recommendation spreadsheet. It ends with a cleaner domain, a stronger authority signal, and a content architecture that compounds — in traditional rankings and in AI-generated answers — rather than competing with itself.
Ready to Run This Audit on Your Domain?
Ritner Digital runs content audits for enterprise B2B organizations that need to fix what's suppressing their rankings before investing further in new content production. We deliver a scored URL inventory, a cannibalization map, a prioritized implementation roadmap, and the governance framework to keep the debt from accumulating again.
Let's talk about your content architecture →
Ritner Digital is a Philadelphia-area SEO and AI search agency specializing in generative engine optimization and enterprise SEO for B2B organizations. We work directly — no account managers, no templated plans, transparent pricing from the start.
Frequently Asked Questions
What is a content audit and why does enterprise scale make it different from a standard audit?
A content audit is a systematic evaluation of every page on your website to determine what should be kept, updated, consolidated, or removed based on its contribution to organic search performance, user value, and business outcomes. At small-site scale — a few hundred pages — a content audit is manageable with a spreadsheet and a few days of manual review. At enterprise scale, the same approach breaks down. You're dealing with thousands of pages produced by different teams over many years, complex internal linking structures, competing stakeholder interests over page ownership, and implementation bottlenecks that mean recommendations sit unactioned for months. The framework has to be systematic enough to process volume without manual judgment on every URL, and specific enough to surface the decisions that actually require human expertise. The scoring model and segmentation approach in this post exist specifically to make that scale manageable.
How do I know if my enterprise site has a topical cannibalization problem?
The fastest diagnostic is Google Search Console. Export your performance data at the page level and look for queries where multiple pages from your domain appear in the pages view for the same query. That's the raw signal. The more nuanced version is to look for queries where your ranking position is unstable — bouncing between page one and page two across different days — and where clicking through to the pages view shows different URLs surfacing for the same query on different dates. Google is testing multiple pages from your domain and hasn't settled on which one to treat as authoritative. Position instability combined with impression spread across multiple pages for the same query is almost always a cannibalization problem, not a content quality problem. You can have excellent pages that are suppressing each other simply because there are too many of them covering the same intent.
What's the difference between a zombie page and a page that just needs to be updated?
A zombie page is one that has no path to relevance — zero traffic, zero backlinks, zero conversion events, and no strategic reason to exist. A page that needs updating has some signal of value but is underperforming its potential because the content is stale, thin, or misaligned with current search intent. The practical distinction comes down to two questions: does this page have any authority worth preserving, and does this topic still matter to the business? If a page has inbound links from external domains, those links carry equity that gets lost if the page is removed without a redirect — that's a page to update or consolidate carefully, not to delete. If a page has zero external links, zero traffic, and covers a topic the business no longer operates in, there's nothing to preserve and the fastest path to a cleaner domain is removal with a redirect to the most relevant surviving page.
How long does a proper enterprise content audit take from start to finish?
For a site in the 10,000 to 50,000 page range, the audit itself — inventory, segmentation, triage, and cannibalization mapping — typically takes four to six weeks when run with a dedicated team and clean data access. Implementation is a different timeline entirely and depends more on internal capacity, dev bandwidth, and stakeholder approval processes than on the audit work itself. The high-impact, low-effort actions — noindexing zero-value pages, fixing internal linking, updating meta data on near-page-one content — can often begin in week three while the broader audit is still running. The more complex consolidation and redirect work gets scoped as projects with their own timelines. The realistic expectation for a full-cycle audit — from initial crawl to meaningful implementation of priority recommendations — is three to six months for most enterprise organizations, with measurable ranking improvements beginning to appear four to eight weeks after the first significant changes go live.
Should I remove pages or noindex them and what's the difference?
Removing a page means it no longer exists on the server — anyone who visits the URL gets a 404 or, if you've set up a redirect, gets sent to a different page. Noindexing a page means it stays live and accessible at its URL but carries a directive telling search engines not to include it in their index. The right choice depends on whether the page serves any purpose outside of organic search. A page that exists for operational reasons — a legacy client portal, a terms page that gets referenced in contracts, a location page that's shared in local business directories — should be noindexed rather than removed, because removing it would break those references. A page with no operational function, no external links, and no traffic can be safely removed with a redirect. As a general rule, when in doubt, noindex first and monitor for a quarter before removing — it's easier to reverse a noindex decision than to restore a removed page and rebuild whatever authority it had.
How does fixing content architecture improve AI search visibility and not just Google rankings?
AI retrieval systems evaluate domains holistically before they evaluate individual pages. A domain with clear topical authority — where the content architecture signals expertise in a specific set of topics without fragmentation or contradiction — is more likely to be treated as a credible source by AI systems than a domain where the same topics are covered inconsistently across dozens of competing pages. Cannibalization is a particular problem for AI citation because AI systems trying to synthesize an answer about a topic need to identify the single most authoritative source on that topic. When your domain has five pages that each partially address the same question, none of them send a strong enough authority signal to earn the citation. Consolidating those five pages into one comprehensive, well-structured canonical page dramatically increases the probability that AI systems recognize your domain as the authoritative source — and cite it accordingly. The content audit is the prerequisite for effective GEO, not a separate project from it.
What governance processes should be in place after the audit to prevent content debt from accumulating again?
Three processes matter most. The first is a new content intake checklist that requires every new piece of content to be checked against the existing URL inventory for cannibalization before it's commissioned or published. This is the most important one because it prevents the problem from recurring — most content debt accumulates because new content is produced without visibility into what already exists. The second is a quarterly content performance review that runs the same triage scoring model used in the initial audit against the current URL inventory, flagging new pages that have dropped below the threshold for retention. The third is a crawl health check — monthly or quarterly depending on publishing volume — that identifies new orphaned pages, broken internal links, and indexation anomalies before they compound into structural problems. With these three processes in place the content audit becomes a governance system rather than a recurring emergency project.