Crawl Budget Isn't Dead. It's Just Misunderstood. Here's What Enterprise Teams Get Wrong.
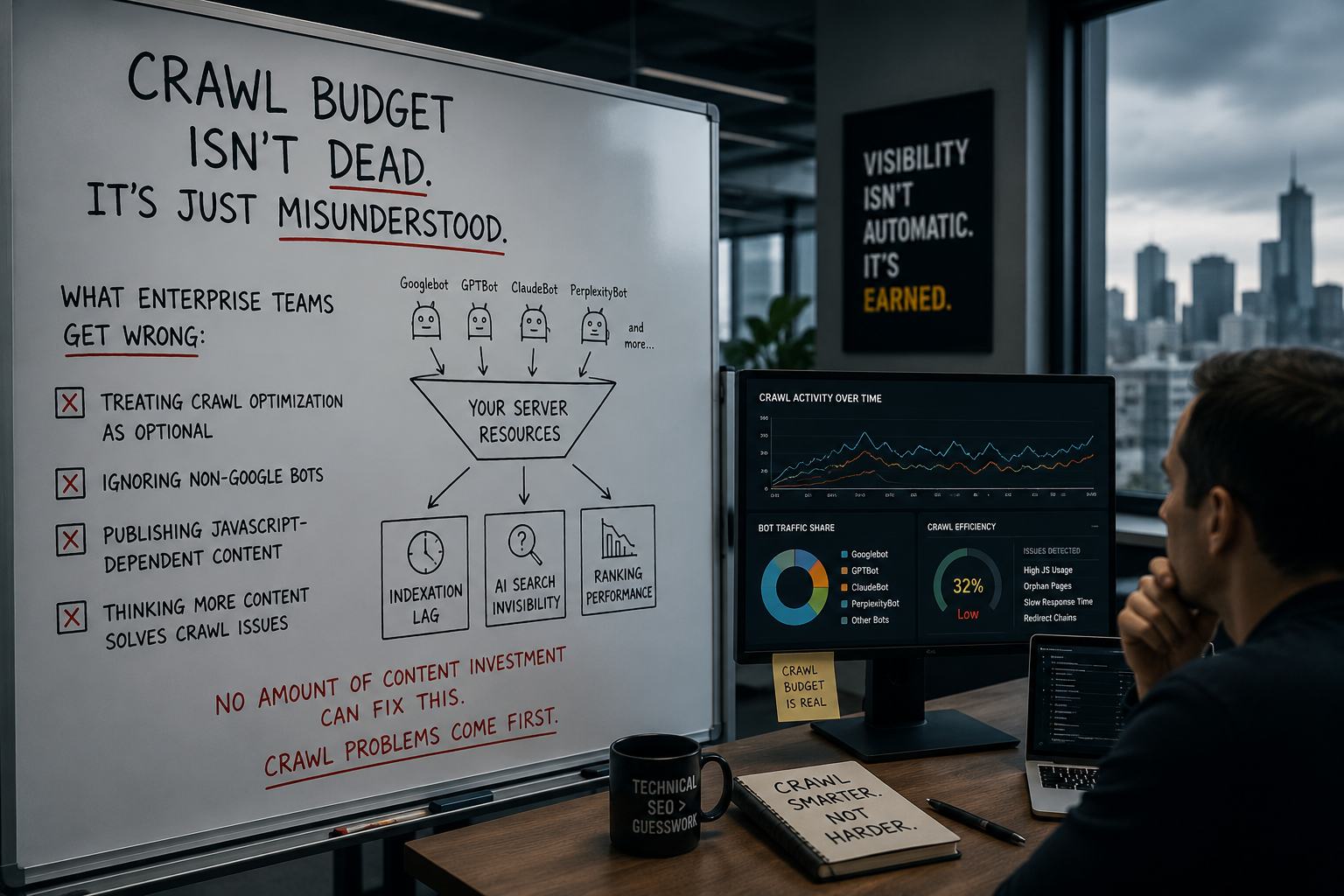
Every few years someone declares crawl budget dead. The argument usually goes something like this: Google's infrastructure has scaled enormously, Googlebot is smarter than ever, and worrying about crawl efficiency is a relic of the era when the web was smaller and search engines were less capable. Just publish good content and Google will figure it out.
This argument was always wrong. In 2026 it is wrong in several new directions simultaneously — because crawl budget has not become less important, it has become more complicated. The number of bots competing for your server resources has multiplied. The consequences of crawl waste have compounded. And the enterprise teams still treating crawl optimization as an optional technical cleanup exercise are discovering that in a search environment where AI search visibility depends on what can actually be crawled and processed, the upstream problem has downstream consequences they cannot optimize their way out of from the content side.
Crawl budget is not dead. It is misunderstood — and for enterprise sites with tens of thousands or hundreds of thousands of URLs, the misunderstanding is costing them in indexation lag, AI search invisibility, and ranking performance that no amount of content investment can fix while the crawl problem persists.
This is the honest technical breakdown of what enterprise teams get wrong and how to get it right.
What Crawl Budget Actually Is — And What It Isn't
Let's start with the definition, because the confusion begins here.
Google's own documentation defines crawl budget as the product of two factors: crawl rate limit and crawl demand. The crawl rate limit is determined by your server's capacity to handle requests without degrading. The crawl demand is determined by how important and fresh Google believes your pages to be. Crawl budget is the number of URLs Googlebot can and wants to crawl. Crawl rate limit is the maximum fetching rate for a given site, determined by the maximum number of simultaneous parallel connections Googlebot can use and the health of the site. If the site is slow or has server errors, the crawl rate limit will decrease and a lower number of pages will be indexed per site crawl. Pageoptimizer
The first common misconception is treating crawl budget as a fixed number you can look up somewhere. You cannot. There is no crawl budget dashboard. There is no universal number that defines a good crawl budget. What matters is the ratio between how many indexable pages your site has and how many pages Google is regularly crawling. Upward Engine
The second common misconception is that crawl budget matters for every site. It does not. For sites with fewer than a few thousand pages, Google crawls the entire site in a single session. Crawl budget becomes a real SEO constraint only at tens of thousands of URLs, and a critical priority at hundreds of thousands. E-commerce sites, large publishers, news sites, and multi-location directories are the primary sites where crawl budget management directly affects indexation and rankings. Futuristicmarketingservices
If your site has fewer than 10,000 pages and a reasonable technical foundation, redirect your effort to content, links, and entity building. Crawl budget is not your constraint. The rest of this post is for organizations where it is.
The third misconception — the one that does the most damage at enterprise scale — is treating crawl budget as a Googlebot-only concern. In 2026 it is not.
The Bot Ecosystem Has Changed Everything
This is the dimension of crawl governance that most enterprise technical SEO teams have not fully absorbed yet, and it is the most consequential change to the crawl landscape in years.
Crawler traffic is rising across both traditional search and AI systems. Cloudflare reported that AI and search crawler traffic grew 18% from May 2024 to May 2025, with Googlebot up 96% and GPTBot up 305% during that period. As more bots compete for server and rendering resources, crawl governance is no longer optional for large or content-heavy sites. Pageoptimizer
The scale of this shift is striking. OpenAI's ChatGPT-User crawler made 3.6x more requests than Googlebot across a 55-day data sample covering 69 websites from January to March 2026. Combined with GPTBot, OpenAI's crawlers made 142,225 requests: 3.8x Googlebot's volume. Cloudflare
A Q1 2026 analysis across Cloudflare's network found that 30.6% of all web traffic now comes from bots, with AI crawlers and agents making up a growing share. Digital Applied Team
For enterprise teams whose robots.txt files were written three years ago for a Googlebot-and-Bingbot world, this is not a minor update. It is a fundamental change in who is consuming your server resources and what they are doing with the content they find.
The bots now crawling enterprise sites fall into distinct categories with different behaviors, different purposes, and different implications for what you want them to do:
Training crawlers — GPTBot, ClaudeBot, CCBot, Google-Extended — collect content for large-scale model training datasets. Their activity is not tied to real-time queries. They are typically less frequent and their crawl patterns are broader and less targeted than traditional search crawlers. Blocking them prevents your content from contributing to future model training — a content policy and IP decision, not just a technical one. Huckabuy
Search and retrieval crawlers — OAI-SearchBot, PerplexityBot, Claude-SearchBot — power AI-generated answers in real time. These are the bots that determine whether your content appears in ChatGPT search results, Perplexity answers, and similar AI-generated responses. Blocking them is an AI search visibility decision with direct consequences for how often your brand gets cited.
User-triggered fetchers — ChatGPT-User, Perplexity-User — fetch pages on behalf of a specific user making a real-time query. These are not subject to robots.txt because the user is the entity making the request. You cannot control them through robots.txt. They require server-side controls if you need to restrict them. Huckabuy
AI agents — Google-Agent and equivalents — navigate and interact with your site like a human, clicking buttons, filling forms, comparing prices. As a user-triggered fetcher, Google-Agent is exempt from robots.txt rules. You cannot block it like a typical bot. Search Engine Journal
The reason this taxonomy matters for crawl budget is direct: every bot crawling your site is consuming server resources. An enterprise site with an unmanaged bot environment may be allocating significant server capacity to training crawlers that generate no search visibility benefit, while the retrieval crawlers that do affect AI search citation are getting throttled because the server is under load from everything else.
What Enterprise Teams Get Wrong: The Seven Mistakes
1. Treating Crawl Budget as a Rankings Problem When It's a Discovery Problem
The most common enterprise framing of crawl budget is backward. Teams start looking at crawl optimization when rankings drop. By that point, the discovery failure has already happened — pages weren't indexed, content updates weren't recrawled, new inventory sat undiscovered for weeks.
Enterprise SEO teams rarely have a crawling problem in the abstract. They have a prioritization problem at scale. When a site has hundreds of thousands or millions of URLs, the real issue is not whether search engines can reach the domain. It is whether they spend enough time on the pages that matter most to the business. Product detail pages, core category pages, location pages, editorial hubs, and revenue-driving templates all compete for attention against filtered URLs, duplicates, expired inventory, parameter combinations, soft 404s, redirect chains, and low-value pages that keep regenerating across the stack. ALM Corp
The framing shift: crawl budget optimization is not a defensive play to protect rankings. It is an offensive play to ensure that the content and updates your team is producing actually make it into the index at the speed your business requires.
2. Ignoring Crawl Waste From Parameter URLs and Faceted Navigation
This is the single largest source of crawl waste on enterprise e-commerce and directory sites, and it is often generating hundreds of thousands of low-value URLs that are consuming crawl capacity without contributing any ranking benefit.
Filtered URLs, duplicates, expired inventory, parameter combinations, and soft 404s keep regenerating across the stack. That is where crawl budget optimization becomes a business issue, not just a technical SEO exercise. On large sites, crawl waste slows discovery, delays recrawling of important pages, weakens indexation efficiency, and makes it harder for Google to keep up with change. ALM Corp
Filters, faceted navigation, search pages, and session parameters often create infinite crawl paths that bots cannot scan efficiently. A faceted navigation system with ten filter dimensions can theoretically produce millions of URL combinations. Each of those combinations is a request against your crawl capacity. Most of them rank for nothing, provide no unique value, and exist only because the CMS generates them on demand. Enterpriseseo
The fix is not always simple — faceted navigation is technically complex and the crawl controls require coordination between SEO and development. But the impact of getting it right is disproportionate. Reducing crawl waste from parameter URLs can free up enough crawl capacity that important pages are discovered and recrawled within days rather than weeks.
3. Running Sitemaps as CMS Exports Rather Than Governance Documents
Many enterprise sitemap programs are treated as exports rather than governance tools. They include redirected URLs, canonicalized duplicates, noindexed pages, soft 404s, paginated variants, and stale entries that should have been removed months ago. A sitemap should help search engines identify preferred indexable URLs quickly. If it behaves like a dump of everything the CMS knows about, it becomes part of the problem. ALM Corp
A sitemap submitted to Google Search Console is a direct signal about which URLs matter. When it contains redirected URLs, noindexed pages, and soft 404s alongside legitimate content, it dilutes that signal and creates unnecessary crawl requests for URLs that should never have been in the sitemap to begin with.
Enterprise sitemaps should be governed actively — not generated once and automated. That means regular audits to remove pages that no longer exist, de-index, or redirect. It means accurate lastmod timestamps that reflect real content updates rather than the timestamp of the last CMS export. And it means dynamic sitemap generation that applies rules — excluding noindexed pages, redirected URLs, and canonicalized duplicates at the generation level rather than leaving them in for Google to sort out.
4. Misattributing Position Drops from Server Health Issues to Algorithm Changes
Search engines adapt crawl behavior to server health. When a site regularly returns 5xx errors, times out under load, or struggles to fetch robots.txt consistently, crawl capacity drops. This issue is often misunderstood because the homepage may seem fine while template-specific problems continue deeper in the site. ALM Corp
An enterprise site can have excellent server response times at the homepage level and serious performance degradation on deep product category pages or filtered results pages. Googlebot will observe this. When specific templates consistently return slow responses or server errors, crawl frequency for those templates drops — which means ranking changes from those pages may not be caused by algorithm updates at all. They may be caused by Googlebot deciding those templates are not worth crawling frequently.
Log file analysis is the only reliable way to diagnose this. Server logs show the actual response codes and response times that Googlebot observed, not just the ones that show up in synthetic monitoring. The difference between what your uptime monitor reports and what Googlebot actually experienced at 3am on a Tuesday when the server was under load is where a lot of enterprise crawl problems hide.
5. Not Segmenting Bot Traffic in Log Analysis
Log file analysis is the most accurate and least used diagnostic tool available to enterprise technical SEO teams. Most teams that do run log analysis make the same mistake: they look at aggregate bot traffic without segmenting by user agent, which makes meaningful analysis impossible.
Start by isolating user agents so you can compare AI crawlers, Googlebot, and Bingbot. This is critical, because behavior varies significantly across systems. Without segmentation, everything blends together. With it, patterns start to emerge. Huckabuy
The specific segmentation that matters in 2026 goes beyond Googlebot versus everything else. AI-related crawlers fall into distinct groups: training crawlers, search and retrieval bots, and user-triggered fetchers. Each has different objectives, different crawl patterns, and different implications for what you should publish, what you should cache, and what you should write into your robots.txt and llms.txt files. Search Engine Journal
When AI crawlers do appear in logs, the next question is how far they get. It is common to see them limited to top-level pages — the homepage, primary navigation, and a small number of high-level URLs. As you move deeper into the site, crawl activity often drops off, sometimes sharply, even when those pages are important from a business or SEO perspective. This means entire sections can be effectively invisible because they sit outside the paths these crawlers can follow. Huckabuy
For enterprise teams building GEO and AI search visibility, this is the diagnostic that tells you whether your most important content is actually reaching the AI systems you are trying to get cited by — or whether it is effectively invisible to them because of JavaScript rendering dependencies, weak internal linking, or crawl depth problems that Googlebot manages to work around but AI crawlers cannot.
6. Writing Robots.txt for 2019 Instead of 2026
Most robots.txt files were written for a Googlebot-first world. In 2026, your website has over a dozen non-human consumers. Digital Applied Team
The most important AI crawlers in 2026 with distinct purposes include GPTBot — training data for future OpenAI models — OAI-SearchBot — retrieval for ChatGPT search answers — ChatGPT-User — real-time fetch on behalf of a specific user query — ClaudeBot — training data for Anthropic models — Google-Extended — opts into or out of Google AI training separately from Google search indexing — and PerplexityBot — retrieval for Perplexity answers. Search Engine Land
The critical decision that most enterprise robots.txt files have not made is the distinction between training crawlers and retrieval crawlers. Blocking training crawlers is a privacy and IP protection decision — it prevents content from contributing to future model capabilities. Blocking search and retrieval crawlers removes the website from AI answers — it is a visibility decision. One robots.txt rule cannot make both decisions correctly. Search Engine Land
At minimum, have explicit directives for ChatGPT-User, GPTBot, ClaudeBot, Amazonbot, PerplexityBot, Applebot, Bytespider, CCBot, and Google-Extended. Most businesses benefit from allowing retrieval crawlers — ChatGPT-User, PerplexityBot, ClaudeBot — while making explicit decisions about training crawlers based on content policy. Cloudflare
A critical technical constraint that many enterprise teams have not yet accounted for: of the six major web crawlers, only two — AppleBot and Googlebot — render JavaScript. GPTBot, ClaudeBot, PerplexityBot, and CCBot fetch static HTML only. This means that enterprise sites relying heavily on JavaScript for content rendering may be effectively invisible to AI crawlers even when they are perfectly accessible to Googlebot. Your React or Next.js application may look fine to Google because Google renders it. The AI crawlers see a blank page or minimal content and move on. Digital Applied Team
7. Using noindex When robots.txt Disallow Is More Appropriate — And Vice Versa
This confusion is remarkably persistent at the enterprise level, and it has different consequences than teams typically expect.
A noindex tag tells Google not to include a page in its index, but it does not prevent Google from crawling the page. Googlebot will continue to visit pages with noindex tags, consuming crawl budget, just to confirm they still have a noindex directive. This is a significant source of crawl waste on enterprise sites with large volumes of noindexed pages — parameter variants, filtered results, search pages, internal utilities — that could instead be blocked from crawling entirely with robots.txt.
The important caveat: pages that need their link equity to flow should not be blocked in robots.txt — Googlebot cannot follow links on blocked pages. The decision tree is: if a page should pass link equity but not be indexed, noindex. If a page provides no link equity value and should not be crawled at all, block in robots.txt. Most enterprise sites are not making this distinction consistently, and the crawl cost of inconsistency at scale is significant.
The New Crawl Signals That Determine Priority
Understanding what actually drives Googlebot's prioritization decisions within your crawl budget allocation is the foundation of intelligent crawl management. The signals are not secret — Google has documented them — but the enterprise implementation of each is frequently incomplete.
PageRank and internal link authority. Pages with more backlinks and stronger internal link profiles are crawled more frequently. An established site's homepage is crawled multiple times per day. Deep pages with few internal links may be crawled monthly or less. For enterprise sites, this means internal linking is not just an on-page SEO signal — it is a crawl prioritization signal. Pages that matter to the business but are buried in the site architecture will be crawled infrequently regardless of their quality. Futuristicmarketingservices
Change frequency. Google observes how often a page's content changes between visits. Pages that change frequently — news, live pricing, new reviews — are crawled more often. Static pages that never change are crawled progressively less over time. For enterprise e-commerce sites with dynamic pricing and inventory, this is a significant signal. Products that change price or inventory status frequently will naturally attract more crawl attention. Products that have been static for twelve months will be crawled infrequently — which means when they are eventually updated, the update may take weeks to reflect in the index. Futuristicmarketingservices
Server response time and stability. Googlebot monitors server response time. Slow or unstable servers reduce crawl frequency automatically. URLs that return errors, redirects, or duplicates get deprioritized over time. Pageoptimizer
Accurate lastmod in sitemaps. A well-maintained sitemap signals which URLs exist and when they were last updated. Accurate lastmod dates on recently changed pages prompt faster recrawling. Many enterprise sitemap implementations set lastmod to the crawl date or the current date for every URL on every export, which destroys the signal entirely. Googlebot learns to ignore lastmod values that are always "today." The only lastmod values that carry signal are ones that reflect when the page content actually changed. Crawl Vision
The AI Crawl Dimension: What Log Data Tells Us About Behavior
The agentic crawler behavior study that Digital Applied published in April 2026 — covering twelve production sites over thirty days — provides the most granular real-world data available on how different bots actually behave on live sites. For enterprise technical SEO teams, the findings are directly actionable.
GPTBot is the most aggressive crawler in the data, averaging 4,200 hits per site per day. It prefers text-heavy and citable content — blog sections, documentation, about pages. It revisits high-traffic pages every 2.4 days median, and 47% faster for pages with a fresh last-modified header. ClaudeBot sits at 1,800 hits per day with a 6.8-day revisit cadence. PerplexityBot reaches 980 hits per day but only when users are actively querying. The cadence ranking reveals direct content strategy implications: fresh content gets distributed through GPTBot first, through ClaudeBot inside two weeks, and through Google-Extended on a quarterly cycle. Search Engine Journal
The rendering constraint is the most immediately actionable finding. Since GPTBot, ClaudeBot, and PerplexityBot all fetch static HTML only, any enterprise content that requires JavaScript execution to render is invisible to these crawlers. Pages buried behind JavaScript-heavy navigation or weak internal linking are significantly less likely to be accessed by AI crawlers. As a result, the version of your site AI systems interact with is often incomplete. Huckabuy
The audit question this raises for any enterprise team: if you ran curl on your most important pages and looked at the raw HTML response, would the content those pages are supposed to provide actually be present? Or is it JavaScript-dependent? The answer determines whether your content is accessible to the AI crawlers that power the search visibility you are trying to build.
How to Diagnose Your Crawl Budget Problem
The diagnostic sequence for enterprise crawl budget issues follows a consistent path. Start with the data that is already available before moving to more complex tooling.
Step one: GSC Crawl Stats report. Go to Settings → Crawl Stats in Google Search Console. Review average daily crawl requests over a 90-day window — are they trending up, down, or flat? Look at the response codes breakdown. A high percentage of 3xx responses means redirect chains are consuming crawl capacity. 4xx responses indicate pages that are being crawled but returning errors. 5xx responses indicate server-level problems that will cause Googlebot to reduce crawl frequency. Google flags each visit as either a discovery crawl — looking for new content — or a refresh crawl — checking pages it already knows about. If almost everything is refresh crawls with very little discovery, that is a signal that new content is not getting picked up as quickly as it could. Upward Engine
Step two: GSC Index Coverage report. Look at the Pages report and specifically at the "Why pages aren't indexed" section. Prioritize these categories: "Discovered — currently not indexed" — pages Google knows about but has not crawled — and "Crawled — currently not indexed" — pages crawled but rejected, usually due to thin content or duplicate issues — and "Duplicate without user-selected canonical" — unresolved canonicalization. W3era
Step three: Log file analysis. This is where the enterprise-level insight lives, and it is the step most teams skip because it requires more technical setup. Server logs show how search engine bots actually interact with your site. Look for which URLs are being accessed, how frequently they appear, and how that maps to your site structure. This is where the earlier analysis becomes practical — you are not just asking what was crawled, you are asking whether the right things are being crawled. Huckabuy
A practically revealing metric: it is common to find that 30 to 40 percent of crawl requests go to URLs the business would never intentionally prioritize. If your log analysis shows that a third of Googlebot's visits are going to parameter URLs, paginated result sets, or soft 404 pages, you have identified the crawl waste that is delaying your high-value content from being indexed and refreshed at the rate your business requires. W3era
Step four: Render testing for AI crawlers. Use curl to fetch your most important pages and examine the raw HTML. Compare what you see in the raw HTML to what you see in a browser. If significant content exists only in the browser version, that content is invisible to GPTBot, ClaudeBot, PerplexityBot, and every other AI crawler that does not render JavaScript. This is not a hypothetical problem for AI search visibility — it is a deterministic one. If the crawler cannot see it, it cannot cite it.
The Crawl Budget and AI Search Visibility Connection
This is the link that makes crawl budget a business priority rather than a technical maintenance item in 2026.
When crawl budget is managed well, AI systems can access updated pages, extract clear signals, and connect related topics. The benefit is higher chances of being selected as a source for featured snippets, summaries, and direct answers. Proper crawling is no longer just technical SEO — it is a core requirement for AI visibility. Enterpriseseo
AI Overviews, ChatGPT search, and Perplexity all depend on crawled and indexed content. If Googlebot cannot reach and re-process your pages, they will not appear in AI-generated answers regardless of content quality. Three crawl budget habits that directly improve AI search visibility: FAQ schema on key pages — structured data helps AI systems extract and surface answers faster after crawling — frequent lastmod updates in sitemaps — tells crawlers to re-process pages with updated content — and internal linking depth — AI answer engines favor pages with strong topical connections, and orphaned pages never build this signal. W3era
As we have covered in our piece on the entity problem, building AI search visibility requires that your content is not just good but findable, crawlable, and processable by the systems that determine citation. Crawl budget optimization is the infrastructure layer that makes all of that possible. Content and entity investment fails silently when the crawl foundation is not in place.
The enterprise sites that are building durable AI search visibility are the ones that have connected these dots: the technical SEO work that ensures efficient crawling is not separate from the GEO work that earns AI citations. They are the same program, with crawl efficiency as the prerequisite that everything else depends on.
The Maintenance Cadence Enterprise Teams Need
Crawl budget optimization is not a one-time task. Build these checks into your regular technical SEO workflow: weekly — check Google Search Console Crawl Stats for sudden drops or spikes in crawl volume, and monitor Index Coverage for new errors. Monthly — run a full site crawl with Screaming Frog to identify new redirect chains, broken links, and orphan pages. Quarterly — analyze server log files to verify Googlebot is spending budget on priority pages rather than wasting URLs. After major site changes — any time you add new URL parameter structures, launch new sections, or migrate content, re-audit crawl budget impact immediately. Crawl Vision
The addition in 2026 is an explicit AI crawler monitoring layer. At least quarterly, segment your log data to assess whether AI retrieval crawlers — OAI-SearchBot, PerplexityBot, ClaudeBot — are reaching your most important content or being stopped by JavaScript rendering requirements, redirect chains, or depth limits before they get there. The version of your site that AI systems see may be substantially different from the version Googlebot sees — and only log analysis will tell you how different.
Sources cited in this piece:
ALM Corp — Crawl Budget Optimization for Enterprise Sites: A Technical SEO Framework
Upward Engine — Crawl Budget in 2026: SEO's Most Misunderstood Metric
Futuristic Marketing Services — Crawl Budget: Optimize Google's Crawling of Your Site 2026
ClickRank.ai — Manage Crawl Budget: Boost SEO and AI Visibility in 2026
W3Era — Crawl Budget Optimization Guide 2026 for Better Indexing
Wellows — Crawl Budget SEO: A Guide to Faster Crawling and Indexing
Search Engine Land — Why Log File Analysis Matters for AI Crawlers and Search Visibility
No Hacks — The AI User-Agent Landscape in 2026: A Complete Reference
Search Engine Journal — ChatGPT Now Crawls 3.6x More Than Googlebot
Digital Applied — Agentic Crawler Behavior: 30-Day Site Log Study 2026
OPositive News — Technical SEO Audit: 5 New Layers You Need in 2026
Cloudflare Blog — From Googlebot to GPTBot: Who's Crawling Your Site in 2025
SEO Kreativ — robots.txt Guide 2026: Syntax, SEO Best Practices & AI Bots
AI Boost — Log File Analysis for AI Bot Traffic: Uncovering the Invisible Audience
CrawlVision — Crawl Budget Optimization: 7 Ways to Improve Crawling 2026
Astrak Agency — SEO Log Analysis: What Do Bots Reveal About Your Website?
Internal resources referenced:
You Don't Have a Content Problem. You Have an Entity Problem.
Why Enterprise SEO Fails: The Internal Alignment Problem No Agency Will Tell You About
Running an enterprise site with indexation lag, AI search invisibility, or crawl data you cannot explain? The problem is almost certainly upstream of your content. Let's look at the technical foundation together. →
Frequently Asked Questions
How do I know if crawl budget is actually my problem and not something else?
Start with one diagnostic question: open your Google Search Console Index Coverage report and look at how many pages are in the "Discovered — currently not indexed" state. If that number is large relative to your total page count, Google knows those pages exist but has not gotten around to crawling them — that is a crawl budget constraint, not a content quality problem. The secondary check is to pull the last crawl date on your most important pages using the URL Inspection tool. If revenue-driving product pages or recently updated editorial content show crawl dates that are weeks or months old, your crawl allocation is not reaching the pages that matter most. If your important pages are being crawled frequently but not ranking, the problem is elsewhere — content quality, authority, or on-page signals. Crawl budget optimization cannot fix a content problem. But content investment cannot fix a crawl problem either, and the two are frequently confused at the enterprise level.
What is the single biggest source of crawl waste on enterprise sites?
Faceted navigation and URL parameters, without question. An e-commerce or directory site with ten filter dimensions — color, size, price range, rating, material, brand, location, availability, sort order, and pagination — can theoretically generate millions of URL combinations. Each of those combinations is a valid HTTP request that Googlebot may attempt to crawl. Most of them return near-duplicate content, rank for nothing, and exist only because the platform generates them dynamically. The fix requires coordination between SEO and development to implement crawl controls — typically a combination of robots.txt disallow rules for parameter patterns, canonical tags pointing filtered results back to the canonical category page, and in some cases JavaScript-based parameter handling that keeps filtered URLs out of the crawlable URL space entirely. Getting this right typically produces the largest single improvement in crawl efficiency available to an enterprise e-commerce site, and it frees up crawl capacity that can be redirected toward new products, updated inventory, and high-priority content.
What is the difference between noindex and robots.txt disallow — and which should I use when?
The decision comes down to link equity. A noindex tag tells Google not to include the page in its index, but Googlebot still crawls it — consuming crawl budget on every visit to confirm the tag is still there. A robots.txt disallow prevents Googlebot from crawling the page at all, which saves crawl capacity but also means Googlebot cannot follow any links on that page. The practical rule: if a page has links you want Googlebot to follow and pass authority through, use noindex, not robots.txt. If a page has no link equity value and you simply want to stop wasting crawl capacity on it, block it in robots.txt. The most common enterprise mistake is using noindex across large volumes of parameter pages and filtered results that have no meaningful link value, generating ongoing crawl waste that a robots.txt rule would eliminate entirely. Audit your noindexed page inventory and ask whether any of them are generating link equity that needs to flow. Most of them are not, and most of them should be blocked from crawling altogether.
Why do AI crawlers matter for crawl budget decisions when they aren't Googlebot?
Because they compete for the same server resources. If your server is handling 4,200 daily requests from GPTBot, 1,800 from ClaudeBot, and hundreds more from PerplexityBot and other AI crawlers, that load affects the server response times that Googlebot observes — and Googlebot reduces its crawl frequency when it sees slow or inconsistent responses. Beyond the server load question, AI crawlers are now a search visibility surface in their own right. PerplexityBot and OAI-SearchBot determine whether your content appears in Perplexity and ChatGPT search answers. If your robots.txt is blocking those retrieval crawlers — either intentionally with outdated directives or accidentally because the file was written before these bots existed — you are opting out of AI search citation without having made that decision consciously. The bot ecosystem your crawl governance needs to account for in 2026 is substantially larger than it was two years ago, and most enterprise robots.txt files have not been updated to reflect it.
How does JavaScript rendering affect AI crawler access to enterprise content?
Directly and consequentially. Of the major AI crawlers active in 2026 — GPTBot, ClaudeBot, PerplexityBot, CCBot — none of them render JavaScript. They fetch static HTML only. Googlebot renders JavaScript using headless Chromium, which is why content that loads dynamically via JavaScript is visible to Google but invisible to AI crawlers. For enterprise sites built on React, Next.js, or other JavaScript-heavy frameworks where significant content is rendered client-side, this creates a version of your site that AI systems see that may be substantially different from the version your users and Googlebot see. Product descriptions, pricing, inventory status, review content, and FAQs that are loaded dynamically are all effectively invisible to the AI crawlers that would otherwise be citing them. The diagnostic is simple: use curl to fetch your most important pages and examine the raw HTML response. If the content you want AI systems to cite is not present in that raw HTML, AI crawlers cannot see it regardless of how well you have optimized everything else.
What should our robots.txt actually look like in 2026?
At minimum it should have explicit, deliberate directives for every major AI crawler — GPTBot, OAI-SearchBot, ChatGPT-User, ClaudeBot, PerplexityBot, Google-Extended, Bytespider, CCBot, and Applebot-Extended — with each directive reflecting a conscious decision about what you want that crawler to do. The critical strategic distinction is between training crawlers and retrieval crawlers. Training crawlers like GPTBot and ClaudeBot collect content for model training datasets — blocking them prevents your content from contributing to future AI model capabilities, which is a content policy and intellectual property decision. Retrieval crawlers like OAI-SearchBot and PerplexityBot power AI search answers in real time — blocking them removes your content from ChatGPT and Perplexity results, which is a visibility decision. One blanket rule cannot make both decisions correctly. For most businesses, the defensible default is to allow retrieval crawlers and make an explicit, informed decision on training crawlers based on content policy rather than leaving the defaults in place and hoping for the best.
How does crawl budget affect how often my content updates get reflected in search results?
More directly than most enterprise teams realize, and the lag compounds in ways that create real business problems. When Googlebot's crawl capacity for your site is being consumed by parameter URLs, soft 404s, and redirect chains, it has fewer resources available to recrawl your important pages at the frequency those pages change. A product page whose price changes daily needs to be recrawled frequently for those price changes to appear correctly in search results and AI-generated answers. If Googlebot's crawl allocation for that template has been suppressed because the template historically returns slow responses or because the crawl queue is full of URL variants competing for the same capacity, the update may take days or weeks to appear. For e-commerce sites, this has direct revenue implications — incorrect pricing in search results, out-of-stock products appearing as available, discontinued inventory surfacing in AI-generated product recommendations. Crawl frequency for your most dynamic content is a business requirement, not a technical preference, and the crawl budget work that enables it is what makes the difference.
What is log file analysis and why do most enterprise teams not do it?
Log file analysis is the process of examining your web server's access logs to understand exactly which bots visited your site, which URLs they requested, what status codes they received, and how frequently they returned. It is the most accurate diagnostic available for crawl behavior — more accurate than Google Search Console, which shows you what Google wants you to know, and more accurate than third-party crawl tools, which simulate Googlebot behavior rather than observing it. The reason most enterprise teams do not do it is that it requires infrastructure setup — server logs need to be retained, exported, and analyzed with a tool like Screaming Frog Log File Analyser, Botify, or OnCrawl — and the analysis is not self-explanatory. It surfaces raw data that requires someone who understands crawl behavior to interpret. But the findings are irreplaceable. Log analysis is the only way to see whether Googlebot is spending time on your priority pages or wasting budget on low-value URLs, whether AI crawlers are reaching your important content or hitting JavaScript walls, and whether your recent site changes caused any unintended crawl behavior changes. If your enterprise technical SEO program does not include quarterly log file analysis, you are making crawl prioritization decisions without the most accurate data available to make them.
How do redirect chains affect crawl budget and what is the right way to fix them?
Every redirect hop in a chain is a separate crawl request. A three-hop redirect chain from an old URL to a final destination costs Googlebot three requests to reach one page — three times the crawl capacity of a direct 301. At enterprise scale, where redirect chains often accumulate over years of site migrations, URL restructuring, and platform changes, the aggregate crawl waste from redirect chains can be significant. The fix is straightforward in principle and often complex in execution: audit every redirect using a tool like Screaming Frog, identify every chain of two or more hops, and flatten each chain to a single direct 301 pointing from the original URL to the final destination. The execution complexity comes from tracking the original URLs — which may be scattered across legacy databases, old sitemaps, and external links — and ensuring that flattening the chain does not break any existing functionality. Prioritize the chains on your highest-traffic and highest-authority pages first, since those are the ones where crawl waste has the greatest impact on indexation frequency and link equity flow.
Should we be thinking about llms.txt in addition to robots.txt?
Yes, and the distinction between the two is worth understanding precisely. robots.txt controls whether specific crawlers can access specific URLs on your site — it is a crawl permission document. llms.txt is a proposed standard — not yet an IETF standard but gaining adoption — that provides structured information about your site's content specifically for large language models when they are generating responses. Where robots.txt says "this crawler can or cannot access these paths," llms.txt says "here is what our site contains, here is the content most relevant for AI responses, and here is how to understand our content hierarchy." They operate independently. A site can block a training crawler in robots.txt while still providing an llms.txt to help retrieval systems understand which content is most citable. For enterprise sites with large content inventories where the most important pages are not necessarily the most crawled or the most linked, llms.txt provides a mechanism to communicate content priority to AI systems directly — a complement to the crawl infrastructure work rather than a replacement for it.