AI Recommendations Aren't a Click Curve You Can Extrapolate
For roughly two decades, digital marketing ran on a comforting assumption: that visibility could be modeled. If you knew your position in a search ranking, you knew roughly what traffic to expect. Move from position five to position three, and you could forecast the lift with reasonable confidence. The relationship between rank and clicks was stable enough that an entire industry built planning, budgeting, forecasting, and quarterly reporting on top of it. You could draw the curve, extrapolate along it, and tell a client what next quarter would probably look like — and you'd usually be close.
That world is quietly ending. When a customer asks ChatGPT, Gemini, Perplexity, or Google's AI Mode for a recommendation, the system that answers does not behave like a ranking algorithm. It behaves like something fundamentally less predictable — and treating it as though it were just "SEO with extra steps" leads businesses to plan around a curve that doesn't exist. This piece walks through why that's the case, what the data actually shows, and — most importantly — what a business should do instead of trying to forecast the unforecastable.
The Old Model Worked Because Search Was (Mostly) Deterministic
To understand what's broken, it helps to be precise about what used to work and why.
Traditional search optimization rested on a kind of stability that, in retrospect, we took for granted. Whereas SEO visibility typically oscillates along a deterministic ranking spectrum, GEO visibility is subject to far greater instability. In practical terms: if you ranked third for a query on Google, you ranked third for nearly everyone searching that query, and you held that spot until something measurable changed in your content, your backlinks, or the competitive field. As one practitioner put it plainly, when you rank #3 on Google, you're #3 for everyone who searches that query, roughly. arxivMedium
That consistency is exactly what made forecasting possible. Click-through rates by position were well-studied, widely published, and reasonably durable from quarter to quarter. Because the system was stable, you could observe cause and effect directly — tweak anchor text or link velocity and watch positions shift in Search Console. Inputs mapped to outputs in a way you could measure, repeat, and trust. You could build a model, and the model would hold long enough to be useful for planning. Strapi
This is the deep structure behind the phrase "click curve." A curve implies a stable, continuous relationship between a variable you control (rank) and an outcome you care about (clicks). Extrapolation — the whole basis of forecasting — only works when that relationship persists. The entire practice of SEO forecasting was, in essence, a bet that the curve would stay roughly the same shape tomorrow as it was today. For a long time, that was a good bet.
Why AI Recommendations Resist the Same Treatment
The shift to AI-generated answers breaks this bet in two compounding ways. The first is about the nature of the underlying technology. The second is about how that nature shows up in measurable, real-world behavior.
Reason One: The Underlying Systems Are Non-Deterministic by Design
Large language models don't retrieve a fixed answer from a table; they generate one, token by token, by sampling from a probability distribution. LLMs generate text based on probabilities derived from their training data. At each step in the generating process, the model predicts the next word by sampling a probability distribution of next token likelihood. The consequence is that the same prompt can — and routinely does — yield different outputs on different runs. This isn't a bug to be patched; it's a property of how the systems work. arxiv
A common misconception, even among technically sophisticated marketers, is that setting the model's "temperature" parameter to zero makes it deterministic. It does not. Temperature 0 is a sampling parameter, not a determinism guarantee. The model providers themselves are explicit about this. The Claude API can produce slightly different outputs across calls even with identical inputs and temperature 0, and OpenAI states that their API can only be "mostly deterministic" regardless of the temperature value. MediumUnstract
Why can't they simply guarantee repeatability? The reasons are partly architectural and run deeper than any single setting. Non-determinism in LLMs comes from probabilistic random sampling, the unpredictable order of subsystem execution in parallel systems, and differences in floating point arithmetic implementation. When you run these models on shared, heterogeneous cloud hardware at enormous scale, perfect bit-for-bit repeatability simply isn't available. And these small variations don't stay small — in multi-step reasoning, setting temperature to zero still leads to high unreliability due to the compounding effect of subtle non-determinism over tokens and turns. A tiny difference early in the generation ripples outward into a different word, which leads to a different sentence, which can lead to a different recommendation entirely. arxivarxiv
For a business, the implication is stark and worth sitting with: there is no stable "position" to occupy in the first place. Unlike traditional SEO, where rankings shift gradually over time, AI search results can change from one query to the next. You are not climbing a ladder with fixed rungs. You're trying to be selected by a system that re-rolls the dice every time someone asks. AirOps
Reason Two: Visibility Fluctuates Even When Nothing Changes
This is not a theoretical or academic concern. It has been measured at scale, repeatedly, by independent researchers — and the numbers are sobering.
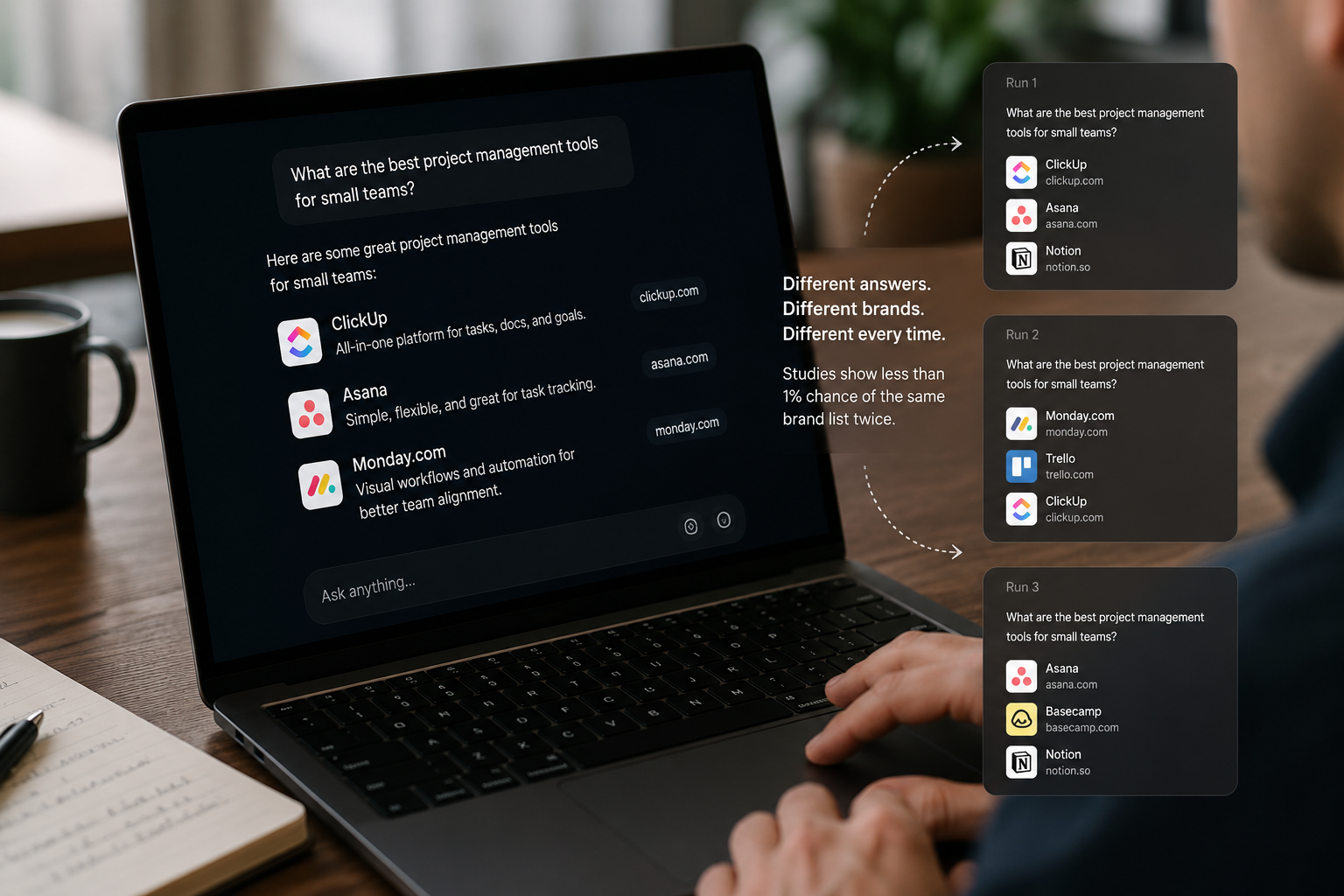
In one analysis of more than 45,000 citations drawn from 800 queries run multiple times, researchers found that consistent visibility is the exception, not the norm; on average, only 30% of brands remained visible in back-to-back responses, and about 57% of brands that disappeared from one response resurfaced in a later run. Read that again: a brand could vanish from the answer entirely and then reappear later, with no change to the brand, the content, or the query — purely as a function of the system's variance. AirOps
Other independent studies converge on the same picture. Otterly.AI's research found that only 30% of brands maintain visibility from one AI response to the next, and just 20% remain visible across five consecutive runs. SparkToro's study of 2,961 prompts found less than a 1% chance of getting the same brand list twice. Less than one percent. The answer itself is in constant motion, too — AI Overview content changes roughly 70% of the time for the same query, and when the answer updates, almost half of the citations are replaced with new sources. MediumSuperlines
On top of run-to-run randomness, results also vary systematically by context. The same question produces different answers for different people in different places. The location where a user submits a query can influence how the model shapes its response — a query like "best accounting software" in London may feature UK vendors, while the same query in New York highlights US companies. The output depends on who is asking, where they are, which platform they're on, what they asked earlier in the conversation, and the luck of the sampling draw. None of those variables existed in the old ranking model, where position three was position three for everyone. AirOps
You're Measuring Probability, Not Position
This is the conceptual leap that trips up businesses carrying over an SEO mindset, and it's worth stating as directly as possible. The old metric was a position — a single, checkable, durable fact. The new metric is a probability — a distribution you can only estimate by sampling repeatedly and observing the spread.
This reframing has immediate, practical consequences. The most important: a single check tells you almost nothing. If you run one query in ChatGPT today and see your brand cited, that tells you almost nothing; you need multiple runs per query per provider across multiple days to get a statistically valid signal. The discipline shifts from reading a rank to estimating a likelihood — as the same analysis puts it, you're measuring citation probability, not citation position. A serious audit treats each query the way a pollster treats a survey question: it runs it many times and reports a rate with a margin of error, not a single observation stated as fact. MediumMedium
This is precisely why a click curve is the wrong mental model, not just an imperfect one. A click curve assumes a fixed, extrapolable relationship between a lever you pull and a result you get. AI recommendation behavior is a probability distribution that reshuffles per query, per user, per platform, and per run. You cannot extrapolate a stable trend from a system whose defining mathematical property is that it doesn't repeat itself. Forecasting it like a curve isn't merely optimistic — it's a category error.
It Gets More Complicated: The Platforms Don't Agree With Each Other
Even if you could somehow average away the run-to-run variance, you'd still face a second problem: there is no single "AI search" to optimize for. The major platforms are built differently, retrieve differently, and therefore surface different sources.
The source mix that makes a brand visible in Gemini is not the same mix that makes it visible in Claude. Businesses treating AI search as a monolith are optimizing for an average that doesn't exist. The architecture drives the behavior in ways that matter. Perplexity functions as a search engine, triggering a web search against its own index for each query, which gives it relative consistency, while other systems rely on retrieval layers configured differently for different query types. One engine might behave like a stable librarian; another like a long-tail editorial curator; another like a broad commercial aggregator. The differences between them can be enormous. YextYext
There is, however, a genuinely useful nuance buried in the complexity — and it points toward a smarter strategy. While the sources engines cite differ wildly, the brands they ultimately name can be more consistent than you'd expect. The engines do behave differently, in some cases by close to two orders of magnitude, but the consistency on the output side — which brands get named in the final answer — tells a different story. The strategic takeaway isn't "build a separate playbook for every engine." It's that you need to understand which source layers feed the answers across engines, and earn authority within those layers, rather than chasing the surface-level quirks of any one platform. BrightEdge
Citations and Mentions Are Not the Same Thing — and the Difference Has Teeth
Another place the old vocabulary fails us: in classic SEO, a result was a result — you were on the page or you weren't. In AI answers, there are distinct ways to appear, and they do entirely different jobs for your business. Citations drive traffic. Mentions build association. You need both metrics because they move differently and have different business consequences. Medium
This distinction is not academic. You can be the very source an AI leans on to build its answer and still lose the actual recommendation. Picture the scenario: you publish the definitive guide on a topic, complete with original research and data, and you earn the citation for it. Then a prospect asks "what tool should I use?" and the AI recommends your competitor, using your research to justify the choice. You did the work; your competitor got the customer. A naive appearance-rate metric would score that as a win. RankScience
It gets sharper still. A simplistic "are we visible?" metric can completely mask whether that visibility is helping or hurting you. Zero visibility and bad visibility look identical if you only measure appearance rate — a brand that appears in every AI response but gets described as "overpriced and unreliable" is losing faster than a brand with 30% visibility and consistently positive framing. Sentiment and framing, not just presence, are now part of the measurement problem. Being mentioned is not automatically good; it depends entirely on how. Medium
Why This Matters More Than the Raw Traffic Numbers Suggest
A skeptic might reasonably push back here: if AI search sends so little traffic, why obsess over its unpredictability? It's a fair question, and the answer is what makes this whole shift urgent rather than optional.
It's true that the raw volume is still small. AI search drives under 1% of total web referral traffic on most sites, with Similarweb's 2026 data placing AI referrals at around 0.13% of total website visits on average. If you stopped there, you'd conclude AI search is a rounding error. You'd be making an expensive mistake — for two reasons. Getpassionfruit
First, the trajectory is near-vertical. AI-referred sessions grew 527% in five months across 400+ websites studied, making AI search referral traffic the fastest-growing traffic source on the web. Meanwhile the ground is shifting under traditional search: Google AI Overviews appeared on 48% of all search queries as of March 2026, up from about 13% a year earlier, and AI Overviews reduce organic click-through rates substantially. The zero-click reality is now the dominant reality — 64.82% of Google searches now end without a click, a figure that has climbed steadily from 50% in 2019. Whether or not you've decided to care about AI search, your traditional search traffic is being reshaped by it. theStacc + 2
Second — and this is the part most teams miss — that tiny sliver of AI traffic converts dramatically better than anything else. The numbers are almost hard to believe. Ahrefs found that AI search visitors convert at 23x the rate of traditional organic — 0.5% of their traffic drove 12.1% of all signups — and Semrush's 2026 data shows a 4.4x average conversion advantage across industries. These visitors behave differently once they arrive, too: AI-referred visitors spend 68% more time on-site, and they buy, book, and submit forms at far higher rates. The logic is intuitive once you see it — someone who arrives after an AI has already answered their preliminary questions and recommended you is a far warmer prospect than someone idly clicking a blue link. AveriEmarketed
So the stakes are not "a small traffic channel that happens to be noisy." The stakes are "the fastest-growing and highest-converting discovery channel, and it happens to be one you cannot forecast with your existing tools." That combination is exactly why the click-curve instinct is so dangerous: it leads you to under-invest in the channel that matters most, or to measure it so badly that you draw the wrong conclusions.
A fair caveat is warranted here, because honest measurement is the whole point of this piece. The conversion figures vary by methodology and industry, the sample sizes are often small enough to be volatile, and attribution is genuinely hard — roughly 40 to 60% of AI-generated responses lack visible source attribution, and much AI-influenced activity never registers as referral traffic at all. The precise multiples should be treated as directional, not gospel. But the direction is consistent across every independent study: small volume, high intent, explosive growth, difficult attribution. Runmarshal
So What Should a Business Actually Do?
If you can't forecast AI recommendations like a click curve, it would be easy to conclude you're powerless. You're not. The conclusion is narrower and more useful than that: the strategy shifts from gaming a rank toward earning durable authority and measuring honestly. Here's what that looks like in practice.
Build the Inputs That Models Consistently Reward
The genuinely encouraging news is that the fundamentals weren't thrown out — they were promoted. SEO lays the foundation for better success in AI search visibility; clear structure, authority signals, and fact-rich content help AI recognize your content. Several patterns recur across the research with enough consistency to act on. Content with statistics, citations, and quotations achieves 30–40% higher visibility in AI responses; pages updated within two months earn 28% more citations than older content; and pages with well-organized headings are 2.8x more likely to earn citations. Format matters as well — listicles see roughly a 25% citation rate compared to about 11% for standard blog and opinion pieces, and "best," "top," and "vs" content tends to drive the highest AI traffic. WordStream + 2
Crucially, this authority is earned, not bought. 90% of AI citations driving brand visibility originate from earned and owned media, not paid placements. You build it by being genuinely useful, well-structured, factually dense, current, and clearly authoritative — which, not coincidentally, is what good content was always supposed to be. Superlines
Measure Like a Statistician, Not an Auditor
Because visibility is probabilistic, your measurement has to be built around that fact from the ground up. That means building measurement practices that account for fluctuation, identify patterns, and separate real signal from noise. Concretely: run each query multiple times, across multiple platforms, on multiple days, and report a rate rather than a snapshot. Track citation rate and mention rate separately, because they do different jobs. Watch sentiment and framing, not just presence. And segment AI referral traffic in your analytics so its outsized conversion value doesn't get buried inside "organic" or, worse, misattributed as direct traffic. The honest version of this work produces probability ranges and trend lines, not the tidy single numbers executives are used to — and part of the job is resetting that expectation. AirOps
Don't Abandon Traditional Search — Integrate It
This is an expansion of the playbook, not a replacement of it. SEO remains important and impactful, and when paired with generative engine optimization, marketers can build on what they've already established. The two are mechanically linked: nearly 40% of Google's AI Overviews rank in the top 10 organic search results, and nearly 70% rank in the top 100. In other words, strong traditional fundamentals are often what feed the AI answers in the first place. The good news for resource-strapped teams is that the same content engineering that earns one channel tends to earn the other — what changes most is the measurement layer, not the underlying craft. JasperJasper
The Bottom Line
The instinct to model AI recommendations like a click curve comes from an understandable place — it's how marketing has worked for twenty years, and the muscle memory is strong. But the underlying machinery is different in kind, not merely in degree. These systems are non-deterministic at their core; they vary by user, place, platform, conversation, and the luck of the draw; and they reward genuine authority and clarity over keyword mechanics. These context signals make results more dynamic and tailored for users, but they also introduce additional complexity and unpredictability for brands trying to manage visibility. AirOps
You cannot extrapolate a curve from a system designed not to repeat itself. What you can do is build authority that models reliably reward, structure your content so they can use it, measure the probability distribution honestly instead of pretending it's a fixed point, and capture the disproportionate value of the high-intent traffic AI sends your way. The businesses that internalize this early — that stop forecasting positions and start managing probabilities — will be the ones that AI keeps recommending while their competitors are still staring at a curve that no longer exists.
Ready to build a real AI-search strategy instead of guessing at a curve? Ritner Digital helps businesses earn durable visibility — and capture the high-converting traffic that comes with it — across AI search and traditional search alike. Get in touch with us →
Frequently Asked Questions
What does it mean that AI recommendations are "non-deterministic"?
It means the same question can produce different answers on different runs, even with no change to your content or the query. LLMs generate text by predicting the next word from a probability distribution rather than following a set pattern. This isn't a flaw to be fixed — it's how the technology works. Even the strictest settings don't eliminate it; temperature 0 is a sampling parameter, not a determinism guarantee. arxivMedium
Can't I just set the temperature to zero to get consistent results?
No. This is one of the most common misconceptions. The model providers say so directly: the Claude API can produce slightly different outputs across calls even with identical inputs and temperature 0, and OpenAI states their API can only be "mostly deterministic." The variability comes from deeper sources, including the unpredictable order of subsystem execution in parallel systems and differences in floating point arithmetic. Unstractarxiv
How much does AI visibility actually fluctuate?
A lot — and it's been measured. On average, only 30% of brands remain visible in back-to-back AI responses, and about 57% of brands that disappear from one response resurface in a later one. Across repeated runs the instability is even starker: SparkToro's study of 2,961 prompts found less than a 1% chance of getting the same brand list twice. AirOpsMedium
If I check ChatGPT once and see my brand, am I winning?
Not necessarily — a single check is close to meaningless. If you run one query in ChatGPT today and see your brand cited, that tells you almost nothing; you need multiple runs per query per provider across multiple days to get a statistically valid signal. You're measuring a probability, not reading a fixed position. Medium
Do I need a separate strategy for each AI platform?
Not quite. The engines do pull from different sources — the source mix that makes a brand visible in Gemini is not the same mix that makes it visible in Claude — but the brands they ultimately name tend to be more consistent. The engines behave very differently, but the consistency on which brands get named in the final answer tells a different story. The smarter move is to earn authority across the source layers that feed all the engines, rather than chasing each platform's quirks. YextBrightEdge
What's the difference between a citation and a mention?
They do different jobs. Citations drive traffic; mentions build association. You need both because they move differently and have different business consequences. You can even be cited as a source while a competitor gets the recommendation — a prospect asks "what tool should I use?" and the AI recommends your competitor, using your research to justify the choice. MediumRankScience
AI search sends so little traffic. Why should I care?
Because the volume is small but the trajectory and value are enormous. AI-referred sessions grew 527% in five months, making AI search the fastest-growing traffic source on the web. And it converts far better than anything else: Ahrefs found AI search visitors convert at 23x the rate of organic, and Semrush's 2026 data shows a 4.4x average advantage across industries. These visitors also spend 68% more time on-site. theStacc + 2
What kind of content actually gets cited by AI?
Content that is structured, factual, current, and authoritative. Content with statistics, citations, and quotations achieves 30–40% higher visibility, pages updated within two months earn 28% more citations, and pages with well-organized headings are 2.8x more likely to be cited. Format matters too — listicles see roughly a 25% citation rate versus about 11% for standard blog and opinion pieces. And it's earned, not bought: 90% of AI citations originate from earned and owned media, not paid placements. Superlines + 2
Does this mean traditional SEO is dead?
No — it's the foundation. SEO remains important, and when paired with generative engine optimization, marketers can build on what they've already established. The two are linked: nearly 40% of Google's AI Overviews rank in the top 10 organic results, and nearly 70% rank in the top 100. Strong fundamentals often feed the AI answers directly. JasperJasper
How should I measure AI search performance?
Like a statistician, not an auditor. Build measurement practices that account for fluctuation, identify patterns, and separate real signal from noise. Run each query multiple times across platforms and days, track citation and mention rates separately, watch sentiment, and segment AI referral traffic in your analytics — especially since 40 to 60% of AI responses lack visible source attribution and much AI-influenced activity never registers as referral traffic. AirOpsRunmarshal